🌘 Le World Wide Web
Le World Wide Web est une immense collection d’informations et de données accessibles via Internet en utilisant le protocole HTTP (et désormais majoritairement HTTPS). L’accès s’effectue principalement via un navigateur moderne (tel que Firefox, Chrome, Safari ou Edge). Ce système de documents hypertextes connectés par des hyperliens a été introduit au CERN par Tim Berners-Lee.
À titre historique, le tout premier navigateur se nommait WorldWideWeb for NeXT.
🌘 Standardisation et identification
La standardisation du web repose sur deux entités principales :
- IETF (Internet Engineering Task Force) : Définit les protocoles de communication (TCP/IP, HTTP/3, QUIC).
- W3C (World Wide Web Consortium) : Définit les standards du WWW tels que HTML5, CSS, XML, SVG, JSON-LD, etc.
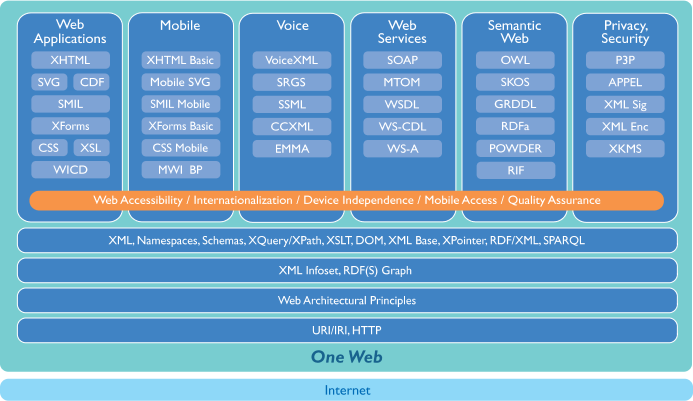
Pour identifier les ressources sur le WWW, on utilise les URI (Uniform Resource Identifier). Il en existe deux types principaux :
- URN (Uniform Resource Name) : Basée sur le nom de la ressource (ex: ISBN pour les livres).
- URL (Uniform Resource Locator) : Basée sur l’adresse d’information de la ressource.
Les caractéristiques essentielles d’une URI sont l’universalité, l’unicité, l’extensibilité et la fixabilité.
🌘 Les époques du web
L’évolution du web se découpe généralement en trois phases :
-
Web 1.0 (Le web statique) : La consommation passive d’information.
- Space Jam (Site original de 1996) - Un vestige historique toujours en ligne.
- CERN - Premier site web (Restauré)
-
Web 2.0 (Le web social et participatif) : L’utilisateur devient créateur de contenu.
-
Web 3.0 (Web sémantique et des données) : Interconnexion des données, API et Knowledge Graphs. (Note : Ce terme est parfois aussi utilisé pour désigner le web décentralisé/blockchain, mais ici nous parlons du sens des données).
🌘 Le Web Sémantique
🌘 Pourquoi un web sémantique ?
Le web actuel a ses limites. Bien qu’il héberge des milliards de documents, les moteurs de recherche traditionnels indexent des mots-clés sans toujours comprendre le sens.
Il devient difficile de trouver de l’information précise ou d’associer de la crédibilité à une source. Un robot (crawler) ne distingue pas naturellement si le mot “Jaguar” désigne l’animal, la voiture ou une version de macOS. Le Web Sémantique vise à structurer ces informations pour que les machines puissent comprendre le contexte.
🌘 Problèmes à résoudre et objectifs
Le web sémantique aborde deux types de problèmes :
- La recherche d’information : Remplacer la recherche par mots-clés par une recherche basée sur des concepts et des relations (Ontologies).
- L’extraction d’information : Permettre aux algorithmes d’agréger des données provenant de sources multiples (ex: répondre à “Qui est la conjointe du président de la France ?” nécessite de comprendre les concepts de “président”, “conjointe” et l’entité “France”).
Les usages actuels incluent les Knowledge Graphs utilisés par Google ou Bing pour afficher des encadrés d’information directe, ou les assistants vocaux (Siri, Alexa) qui interrogent ces données structurées.
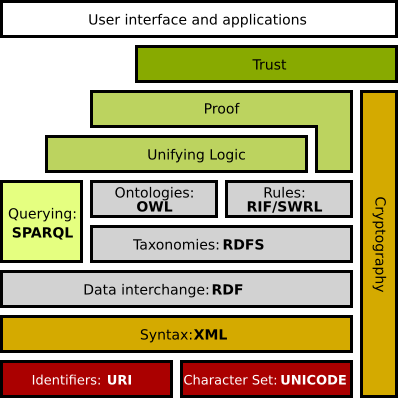
🌘 Composantes du web sémantique
L’architecture repose sur une pile technologique standardisée.
🌘 XML et JSON-LD
Le XML a longtemps été le standard pour transporter des données structurées. Aujourd’hui, le JSON-LD (JavaScript Object Notation for Linked Data) est de plus en plus populaire, notamment pour le référencement Google (SEO).
Exemple classique en XML :
<?xml version="1.0"?>
<annuaire>
<personne class="membre">
<nom>Pelletier</nom>
<prenom>Francois</prenom>
<email>francois@exemple.org</email>
</personne>
</annuaire>🌘 RDF (Resource Description Framework)
Le RDF est le modèle de base du graphe. Il représente tout sous forme de triplets : <Sujet, Prédicat, Objet>.
Le vocabulaire est défini via RDF Schema (classes, propriétés) ou des standards plus récents. Contrairement à une base de données relationnelle (tableaux), le RDF fonctionne comme un graphe flexible.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pers="http://www.monannuaire.com/personne#">
<rdf:Description rdf:about="http://www.monannuaire.com/personne/FP">
<pers:nom>Pelletier</pers:nom>
<pers:prenom>Francois</pers:prenom>
</rdf:Description>
</rdf:RDF>🌘 OWL : Définir les ontologies
OWL (Web Ontology Language) permet de définir des règles logiques complexes (ex: “Si X est l’auteur de Y, alors Y est une œuvre de X”, ou “Un oncle est le frère d’un parent”). C’est ce qui permet à l’ordinateur de faire des déductions automatiques.
🌘 SPARQL
SPARQL est le langage de requête standard (l’équivalent du SQL pour le web sémantique). Il permet d’interroger des graphes de connaissances ouverts sur le web.
Exemple de requête moderne (Interroger Wikidata) :
Cette requête demande “Quelles sont les capitales des pays d’Europe ?”
SELECT ?paysLabel ?capitaleLabel
WHERE {
?pays wdt:P31 wd:Q6256. # Le sujet est un pays
?pays wdt:P30 wd:Q46. # Le pays est en Europe (Continent)
?pays wdt:P36 ?capitale. # Le pays a pour capitale...
SERVICE wikibase:label { bd:serviceParam wikibase:language "fr". }
}🌘 Projets et Outils du web sémantique
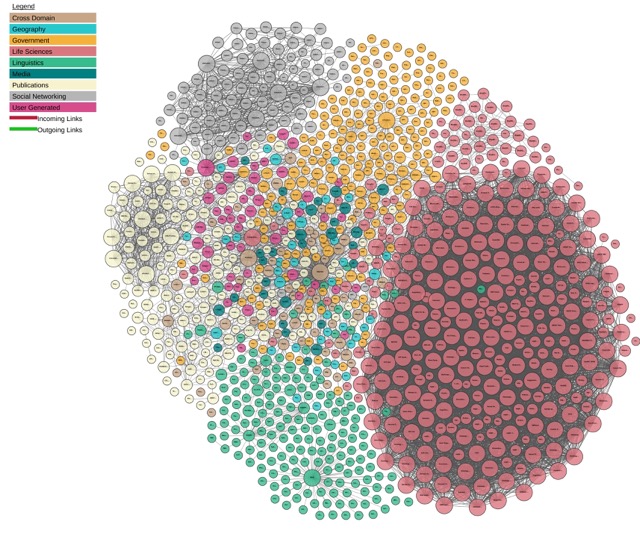
Le Linked Open Data Cloud illustre l’interconnexion des bases de données mondiales.
🌘 Ressources sur les graphes (Actualisées)
Bases de connaissances majeures :
- Wikidata : La pierre angulaire du web sémantique moderne.
- DBPedia : Version structurée de Wikipédia.
- Google Knowledge Graph API : Utilisé pour la recherche Google.
Vocabulaires et Schémas :
- Schema.org : Le standard utilisé par Google, Bing et Yahoo pour comprendre le contenu des pages web (recettes, avis, produits).
- Dublin Core : Pour les métadonnées bibliographiques.
Jeux de données (Datasets) :
- Hugging Face Datasets : Très utilisé en IA aujourd’hui.
- Kaggle Datasets : Pour la science des données.
- Google Dataset Search : Moteur de recherche de données.
🌘 Logiciels libres pour explorer et développer
L’outillage a évolué pour s’intégrer aux langages modernes comme Python et JavaScript.
Outils d’exploration et de visualisation :
- YASGUI : Une interface web moderne pour écrire des requêtes SPARQL.
- Gephi : Un logiciel de référence pour la visualisation de graphes complexes.
- OpenLink Structured Data Sniffer : Extension de navigateur pour voir les métadonnées cachées.
Outils de développement et Bases de données (Triple Stores) :
- Python : La librairie RDFLib est essentielle pour manipuler le RDF en Python.
- Apache Jena : Framework Java robuste.
- Eclipse RDF4J (anciennement Sesame) : Framework Java populaire.
- GraphDB (Ontotext) : Base de données sémantique très performante (version gratuite disponible).
- Neo4j (avec plugin Neosemantics) : Base de données de graphes très populaire qui supporte désormais le RDF.
- Protégé : L’éditeur d’ontologies de référence développé par Stanford.
🌘 Exemples pratiques à essayer
- Wikidata Query Service : Essayez des requêtes en direct sur la plus grande base de données libre du monde. Comprend un assistant visuel.
- DBPedia SPARQL Endpoint : Pour interroger les données extraites de Wikipédia.
- Schema.org Validator : Pour tester si une page web contient des données sémantiques valides.