🌘 TLDR
Cassandra est une base NoSQL distribuée conçue pour supporter des volumes massifs de données avec haute disponibilité et scalabilité horizontale. Cet article présente les avantages et limites du NoSQL, les bases du modèle de colonnes, le théorème CAP et le fonctionnement de Cassandra : keyspaces, tables, partitions. J’explique également comment utiliser le langage CQL, comment connecter Spark pour exécuter des analyses avancées et je fournis un exemple complet avec les données ouvertes des taxis de New-York. Ce guide vise à offrir un aperçu pédagogique du NoSQL moderne, sans promouvoir une solution particulière.
🌘 Introduction
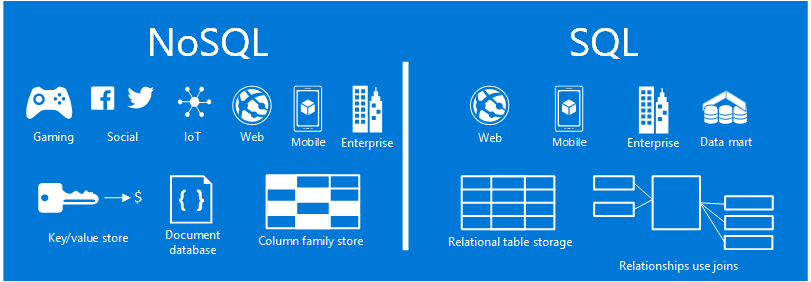
Le NoSQL représente une approche alternative de la modélisation des bases de données. Ce n’est pas nécessairement mieux que les bases de données relationnelles, mais il répond à des besoins différents, entre autres pour les volumes de données importants qui ne peuvent pas être stockés sur un seul serveur.
 Qu’est-ce que Cassandra ?
Qu’est-ce que Cassandra ?
Cassandra est une base de données NoSQL distribuée conçue pour gérer des volumes massifs de données avec haute disponibilité et scalabilité horizontale. Elle s’appuie sur un modèle de colonnes, une réplication automatique et une architecture sans point unique de défaillance.
Note importante: Cet article a été rédigé en 2018. Les concepts présentés restent valides, mais l’écosystème NoSQL a évolué. Cet article garde un objectif éducatif pour comprendre les fondations.
🌘 Pourquoi choisir un NoSQL comme Cassandra plutôt qu’un SGBD relationnel ?
- Modélisation flexible : Les données peuvent être éparpillées, évitant les valeurs manquantes des modèles relationnels
- Distribution native : Gestion automatique de la répartition des données entre plusieurs machines, ce qui permet d’avoir une gestion de la charge plus efficace
- Haute scalabilité : Supporte des volumes de données allant jusqu’aux pétaoctets sans dégradation de performance
- Optimisation pour le web : Stockage et indexation efficace de documents JSON et XML, ce qui est plus difficile pour les bases de données SQL.
🌘 Inconvénients
- Pas de jointures : Les requêtes
JOINne sont pas supportées. Il faut tout modéliser dans une seule table. - Migration complexe : Impossible de migrer directement un schéma relationnel. Il faut repenser à son architecture de données.
- Indexation limitée : Seuls les index sur clés primaires et secondaires sont disponibles. On ne peut donc pas les utiliser facilement pour alimenter des filtres dynamiques.
- Langage spécifique : Souvent intégré à des langages de programmation (Java, Python) sans équivalent SQL standard. On retrouve plusieurs langages dérivés du SQL avec leurs propres particularités.
- Compromis sur la consistance : La plupart des solutions NoSQL ne respectent pas pleinement le principe ACID
🌘 Différence fondamentale
- NoSQL : Approche orientée requêtes. On modélise la base en fonction des besoins d’accès plutôt que des principes de normalisation
- SQL : On utilise les formes normales. Elles sont plus flexible pour l’analyse ad-hoc, mais avec des limitations en termes de performance et de mise à l’échelle.
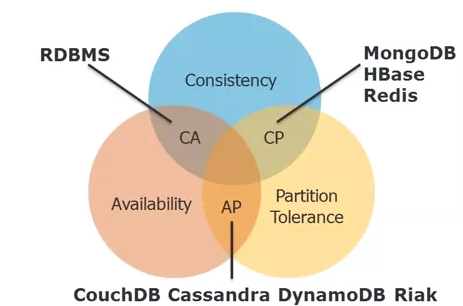
🌘 Théorème CAP
Le théorème CAP établit qu’il est impossible d’avoir simultanément ces trois propriétés dans un système distribué :
- Consistance © : Toutes les requêtes reçoivent des données à jour et cohérentes
- Disponibilité (A) : Chaque requête reçoit une réponse (même si les données retournées ne sont pas à jour)
- Tolérance aux partitions (P) : Le système fonctionne malgré les pannes réseau
Les bases de données NoSQL font généralement un compromis entre ces propriétés selon leur cas d’usage.
🌘 Apache Cassandra

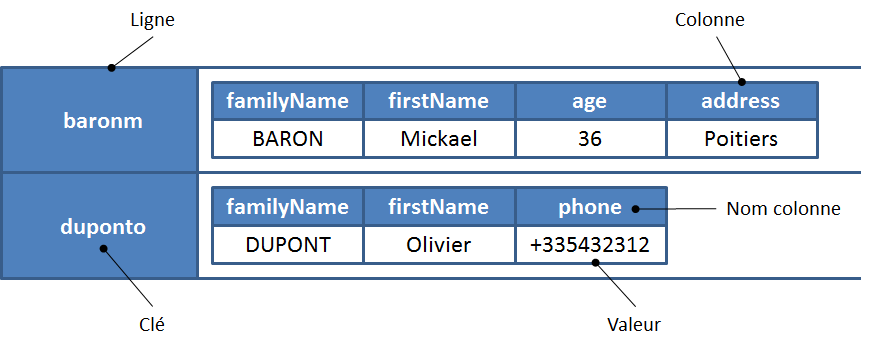
Cassandra est une base de données de type “familles de colonnes” distribuée et hautement disponible :
- Keyspace : Ensemble de clés primaires (analogue à une base de données)
- Tables (Familles de colonnes) : Analogues aux tables dans les bases relationnelles, ce sont les structures qui contiennent les données
- Flexibilité : Une clé primaire n’a pas besoin d’avoir des données dans toutes les tables
- Stockage partitionné : Chaque partition est stockée dans un seul système de fichiers pour des performances analytiques optimales
🌘 Architecture distribuée : comment Cassandra gère la scalabilité
Les données sont stockées sous forme de paires clés-valeurs dans des fichiers partitionnés selon la famille de colonnes et une règle de partitionnement des clés.
Cette architecture distribuée permet d’avoir des données avec le même schéma distribuées sur différents noeuds d’entrée. Ça offre une capacité en écriture très élevée qui est pratique pour :
- La gestion de la journalisation d’infrastructure massive en grande entreprise
- La gestion de données produites par des évènements tels que le streaming, l’internet des objets et des services web
- La haute disponibilité, telle que les données de télécommunication ou de jeu en ligne.
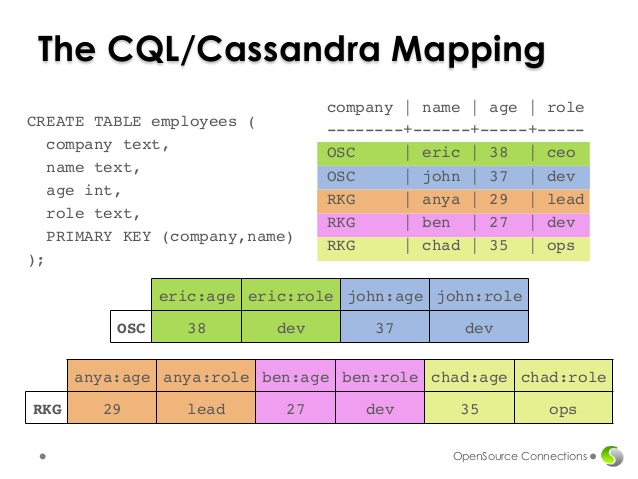
🌘 Le langage CQL
Le langage CQL (Cassandra Query Language) est similaire au SQL mais adapté au modèle de Cassandra :
- Supporte les opérations CRUD (Create, Read, Update, Delete)
- Intègre les concepts de tables (anciennement appelées familles de colonnes) et de keyspaces
- Permet d’interroger efficacement les données partitionnées
🌘 Apache Spark
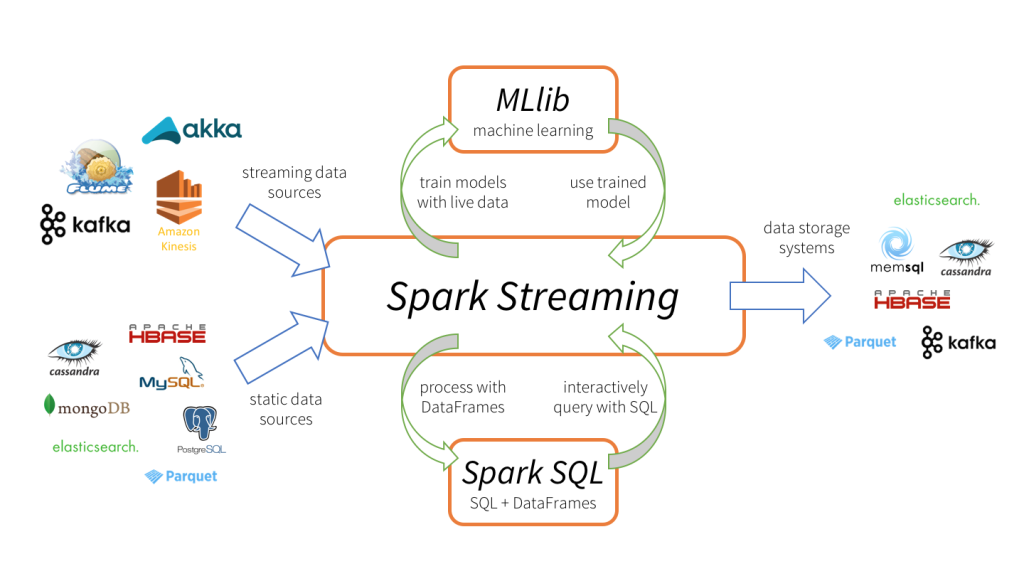
Moteur analytique distribué qui complète bien Cassandra et d’autres bases de données pour les données massives :
- Connexion native avec Cassandra pour lecture/écriture directe
- Traitement parallèle pour des calculs complexes sur de grands volumes
- Jointures possibles entre différentes sources de données, ce que le CQL ne permet pas.
- Support Java et Python (pas simultanément)
- Spark SQL permet d’utiliser du SQL sur des bases NoSQL
Certaines bases NoSQL comme Cassandra ne supportent pas les jointures serveur, mais celles-ci peuvent être simulées via Spark. Ça en fait un complément quasi indispensable.
Tutoriel en français : Bases de données documentaires et distribuées
🌘 Cassandra dans un pipeline analytique moderne (Spark)
Voici une démonstration avec les données ouvertes des taxis de New-York.
🌘 Création du schéma dans Cassandra
Nous allons d’abord créer le schéma dans la base de données Cassandra à l’aide du langage CQL.
CREATE KEYSPACE DEMOTAXI WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
USE DEMOTAXI;
CREATE TABLE demotaxi.trip_fare
(
medallion TEXT,
hack_license TEXT,
vendor_id TEXT,
pickup_datetime TIMESTAMP,
payment_type TEXT,
fare_amount DOUBLE,
surcharge DOUBLE,
mta_tax DOUBLE,
tip_amount DOUBLE,
tolls_amount DOUBLE,
total_amount DOUBLE,
PRIMARY KEY (medallion,pickup_datetime)
);
CREATE TABLE demotaxi.avg_fare_per_medallion
(
medallion TEXT PRIMARY KEY,
avg_fare_amount DOUBLE
);🌘 Chargement des modules requis
Cette première section est le préambule du code, où on charge les modules requis.
import com.datastax.spark.connector.cql.CassandraConnectorConf
import org.apache.spark.sql.cassandra._
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
import spark.implicits._🌘 Initialisation de la connexion à Cassandra
On initialise maintenant la connexion à la base de données Cassandra dans une session Spark. Toute la session va utiliser la source de données spécifiée ici, à moins qu’on en ajoute d’autres en cours de route.
val spark: SparkSession = {
SparkSession
.builder()
.master("local")
.appName("Load Fare Data")
.config("spark.cassandra.auth.username","cassandra")
.config("spark.cassandra.auth.password","motdepasse")
.getOrCreate()
}
// Configurer la connexion à Cassandra
spark.setCassandraConf("Cluster1",
CassandraConnectorConf.ConnectionHostParam.option("adresse_ip") ++
CassandraConnectorConf.ConnectionPortParam.option(9042)
)🌘 Chargement des données CSV
On va maintenant charger les données au format CSV dans une structure de données qui va définir la table que l’on va ensuite écrire dans Cassandra.
Définition du schéma de la structure Row utilisée pour lire les données du fichier CSV :
val trip_fare_schema: StructType = StructType(Array(
StructField("medallion",StringType,true),
StructField("hack_license",StringType,true),
StructField("vendor_id",StringType,true),
StructField("pickup_datetime",TimestampType,true),
StructField("payment_type",StringType,true),
StructField("fare_amount",DoubleType,true),
StructField("surcharge",DoubleType,true),
StructField("mta_tax",DoubleType,true),
StructField("tip_amount",DoubleType,true),
StructField("tolls_amount",DoubleType,true),
StructField("total_amount",DoubleType,true)
)
)Lecture des données :
val trip_fare: DataFrame = {
spark
.read
.option("header","true")
.schema(trip_fare_schema)
.csv("F:\\faredata2013\\trip_fare_1.csv")
}🌘 Écriture dans Cassandra
On va maintenant écrire dans Cassandra.
Écriture dans Cassandra :
{
trip_fare
.write
.mode(SaveMode.Overwrite)
.cassandraFormat(table="trip_fare",
keyspace = "demotaxi",
cluster="Cluster1")
.save()
}
🌘 Lecture depuis Cassandra
On va lire les données que l’on a écrite dans la base de données à l’étape précédente. On va utiliser ici le DataFrame, qui est une structure dite “paresseuse” qui ne va lire les données qu’au besoin.
Lecture depuis Cassandra :
val cass_indexed_trip_fare: DataFrame = {
spark
.read
.cassandraFormat(table="trip_fare",
keyspace = "demotaxi",
cluster="Cluster1")
.load()
}
🌘 Calculs et sauvegarde
On va maintenant effectuer différents calculs et les sauvegarder dans la base de données et sur un fichier.
Imprimer le schéma des données lues dans Cassandra :
cass_indexed_trip_fare.printSchema()Compter le nombre de rangées du DataFrame :
cass_indexed_trip_fare.count()Calculer la moyenne par médaillon :
val avg_fare_per_medallion: DataFrame = cass_indexed_trip_fare.groupBy("medallion").avg("fare_amount").toDF("medallion","avg_fare_amount")Imprimer le schéma du DataFrame calculé précédemment :
avg_fare_per_medallion.printSchema()Enregistrer ces données dans une table Cassandra :
{
avg_fare_per_medallion.
write.
cassandraFormat(table="avg_fare_per_medallion",keyspace = "demotaxi",cluster="Cluster1").
save()
}Sauvegarder sur le disque local :
{
avg_fare_per_medallion.
write.
mode(SaveMode.Overwrite).
option("header","true").
csv("avg_fare_per_medallion.csv")
}🌘 Discussion
Points à considérer pour l’adoption du NoSQL :
- Analytique avancée : Alternative intéressante pour le machine learning
- Coût vs performance : Avantage en temps de traitement vs. coûts matériels
- Migration : Possibilité de migrer les données existantes vers NoSQL
- Architecture applicative : Utilisation de Cassandra pour mieux modéliser selon les besoins clients et analytiques