Ce billet de blog explore comment le logiciel libre R peut être utilisé efficacement en entreprise, particulièrement dans le secteur financier et des assurances. R permet de partager l’expertise et de favoriser la collaboration entre les différents secteurs d’affaires, dont la gestion des risques, le marketing et les opérations. Un de ses principaux avantages est de faciliter l’intégration rapide des nouveaux employés aux projets existants en ne nécessitant pas l’apprentissage d’une technologie propriétaire.
🌘 Avantages de R en entreprise
🌘 Intégration rapide des nouveaux employés
Le logiciel libre R offre plusieurs avantages pour les nouveaux employés :
- Utiliser rapidement les connaissances acquises aux études ou dans un emploi précédent : Les employés peuvent rapidement appliquer les compétences acquises en milieu académique ou dans des emplois précédents
- Intégration plus rapide dans des projets multi-disciplinaires : Une intégration fluide dans des projets multidisciplinaires
- Packages spécifiques au domaine d’expertise : CRAN contient au moins un package de qualité sur votre domaine d’expertise
- Accessibilité : Accessible librement à tous les étudiants et professionnels, multi-plateforme, simple et rapide à installer
🌘 Avantages de la technologie libre
- Économie en formation : Pas d’apprentissage de technologie propriétaire spécifique à un employeur
- Communauté active : Bénéficier d’une base d’utilisateurs en croissance et diversifiée
- Multi-plateforme : Fonctionne de manière cohérente sur différents systèmes d’exploitation
🌘 Fine pointe de la recherche
- Apport de nouvelles techniques rapidement dans l’entreprise : Mettre en œuvre rapidement de nouvelles techniques dans les opérations commerciales
- Permet de résoudre de nouveaux problèmes avant que les solutions commerciales n’apparaissent : S’attaquer aux défis avant que les solutions commerciales ne deviennent disponibles
🌘 Cas d’utilisation pratiques
🌘 Plus proches voisins
Les algorithmes des plus proches voisins sont puissants pour identifier des points de données similaires et fonctionnent exceptionnellement bien avec des données de grande dimension. Ils sont couramment utilisés pour :
- La détection de réclamations avec des caractéristiques similaires
- L’identification de clients ayant des caractéristiques similaires à un groupe d’intérêt
Voici un exemple autonome utilisant le jeu de données intégré iris de R:
# Charger les packages requis
library(RANN)
library(plot3D)
# Utiliser le jeu de données intégré iris
set.seed(123)
data <- iris[, 1:4] # Utiliser seulement les colonnes numériques
# Trouver les plus proches voisins
nn_result <- nn2(data, data, k = 5)
# Visualiser les 3 premières dimensions avec les plus proches voisins mis en évidence
# Sélectionner un point de référence et ses voisins
ref_point <- 1
neighbors <- nn_result$nn.idx[ref_point, ]
# Créer un graphique 3D
points3D(data[ref_point, 1], data[ref_point, 2], data[ref_point, 3],
col = "red", pch = 19, cex = 2, main = "Plus proches voisins")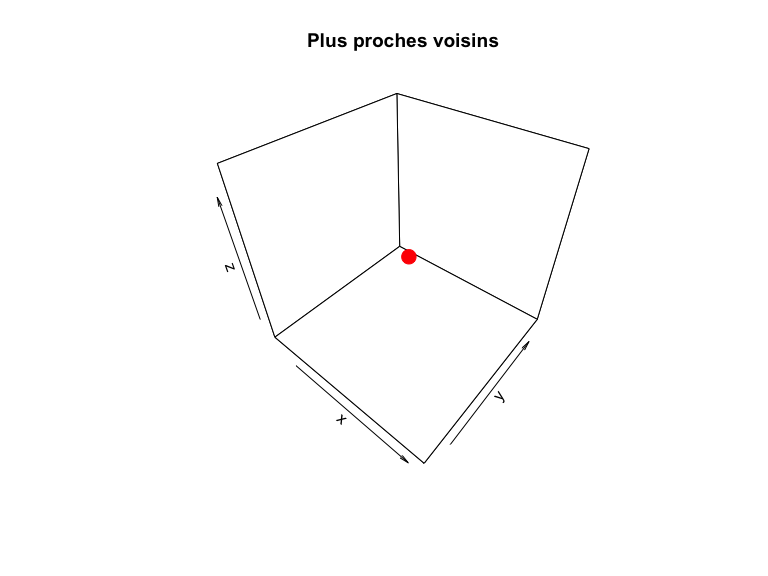
points3D(data[neighbors, 1], data[neighbors, 2], data[neighbors, 3],
col = "blue", pch = 19, cex = 1.5)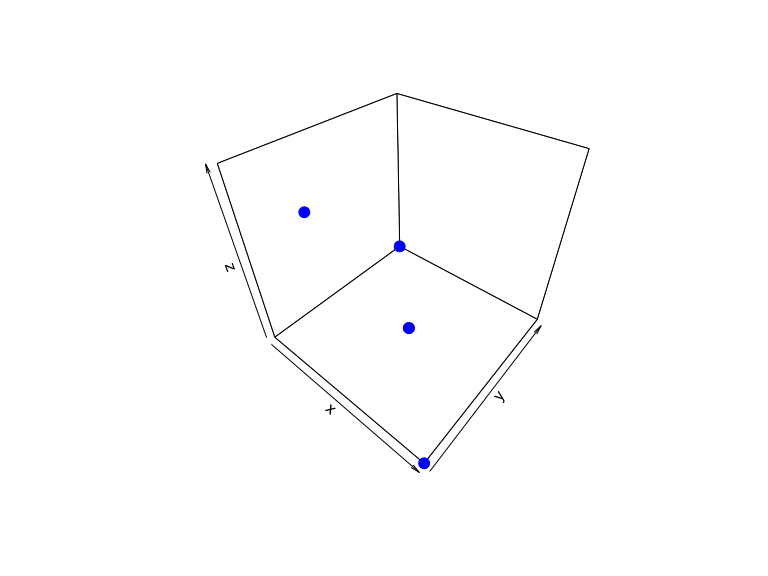
points3D(data[-c(ref_point, neighbors), 1], data[-c(ref_point, neighbors), 2],
data[-c(ref_point, neighbors), 3], col = "gray", pch = 19, alpha = 0.3)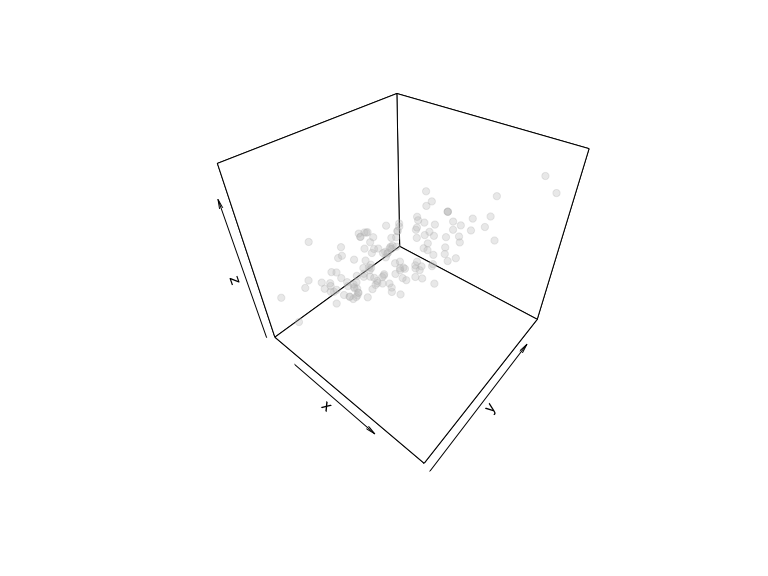
🌘 Modèles XGBoost
XGBoost offre des techniques de gradient boosting de pointe pour la modélisation prédictive. Il est largement utilisé pour :
- L’aide à la décision dans le système de règlement des réclamations
- Le ciblage publicitaire
- Les preuves de valeur avant l’achat de banques de données de fournisseurs externes
Voici un exemple complet utilisant des données synthétiques :
# Charger les packages requis
library(xgboost)
library(caret)
# Générer des données synthétiques
set.seed(42)
n <- 500
synthetic_data <- data.frame(
feature1 = rnorm(n, mean = 10, sd = 2),
feature2 = runif(n, min = 5, max = 15),
feature3 = rnorm(n, mean = 20, sd = 3),
feature4 = rpois(n, lambda = 8),
feature5 = rnorm(n, mean = 5, sd = 1.5)
)
# Créer une variable réponse binaire basée sur les relations entre caractéristiques
synthetic_data$response <- ifelse(
synthetic_data$feature1 + synthetic_data$feature3 > 25 &
synthetic_data$feature2 > 10,
1, 0
)
# Diviser les données
train_index <- createDataPartition(synthetic_data$response, p = 0.8, list = FALSE)
train_data <- synthetic_data[train_index, ]
test_data <- synthetic_data[-train_index, ]
# Préparer les données pour XGBoost
dtrain <- xgb.DMatrix(
data = as.matrix(train_data[, 1:5]),
label = train_data$response
)
dtest <- xgb.DMatrix(
data = as.matrix(test_data[, 1:5]),
label = test_data$response
)
# Définir les paramètres
param <- list(
objective = "binary:logistic",
eval_metric = "auc",
max_depth = 4,
eta = 0.3,
nthread = 2
)
# Entraîner le modèle
watchlist <- list(eval = dtest, train = dtrain)
model <- xgb.train(
params = param,
data = dtrain,
nrounds = 50,
watchlist = watchlist,
print_every_n = 10
) [1] eval-auc:0.987879 train-auc:0.996927
[11] eval-auc:0.998990 train-auc:0.999810
[21] eval-auc:0.999596 train-auc:0.999975
[31] eval-auc:0.999192 train-auc:1.000000
[41] eval-auc:0.999192 train-auc:1.000000
[50] eval-auc:0.999192 train-auc:1.000000 # Importance des caractéristiques
importance <- xgb.importance(feature_names = colnames(train_data[, 1:5]), model = model)
print(importance) Feature Gain Cover Frequency
<char> <num> <num> <num>
1: feature2 0.8221089309 0.439140738 0.27215190
2: feature3 0.1116263957 0.327339864 0.34810127
3: feature1 0.0637769963 0.201077012 0.26582278
4: feature5 0.0016288602 0.025286642 0.08860759
5: feature4 0.0008588168 0.007155744 0.02531646# Tracer l'importance des caractéristiques
xgb.plot.importance(importance)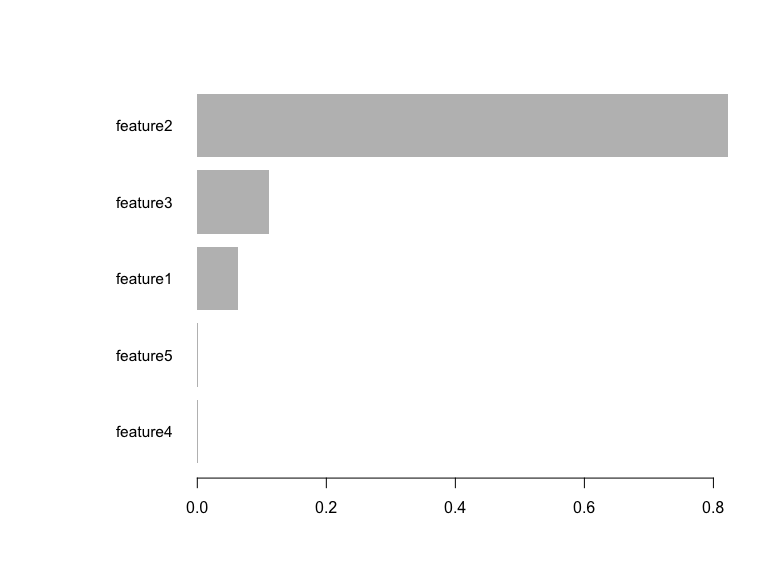
🌘 Analyse marketing
R excelle dans l’analyse marketing, aidant à déterminer quels canaux
publicitaires stimulent l’engagement des clients. Voici un exemple
utilisant des données marketing simulées :
# Charger les packages requis
library(ggplot2)
library(dplyr)
library(lubridate)
library(tidyr)
# Générer des données marketing synthétiques
set.seed(123)
n_days <- 365
dates <- seq(as.Date("2022-01-01"), by = "day", length.out = n_days)
marketing_data <- data.frame(
date = dates,
decimal_date = as.numeric(dates),
seasonality = sin(2 * pi * seq(1, n_days) / 365) * 50 + 100, # Patron annuel
tv_ads = rnorm(n_days, mean = 25, sd = 8),
email = rnorm(n_days, mean = 15, sd = 5),
web_ads = rnorm(n_days, mean = 30, sd = 10),
phone_calls = rnorm(n_days, mean = 10, sd = 3)
)
# Calculer le total des prospects (variable réponse)
marketing_data$total_leads <- rowSums(marketing_data[, 3:6])
# Créer un graphique à zones superposées
ggplot(marketing_data, aes(x = decimal_date)) +
geom_ribbon(aes(ymin = 0, ymax = seasonality, fill = "Saisonnalité"), alpha = 0.7) +
geom_ribbon(aes(ymin = seasonality, ymax = seasonality + tv_ads, fill = "Télévision"), alpha = 0.7) +
geom_ribbon(aes(ymin = seasonality + tv_ads,
ymax = seasonality + tv_ads + email, fill = "Courriel"), alpha = 0.7) +
geom_ribbon(aes(ymin = seasonality + tv_ads + email,
ymax = seasonality + tv_ads + email + web_ads, fill = "Web"), alpha = 0.7) +
geom_ribbon(aes(ymin = seasonality + tv_ads + email + web_ads,
ymax = seasonality + tv_ads + email + web_ads + phone_calls,
fill = "Téléphone"), alpha = 0.7) +
labs(title = "Contributions des canaux marketing dans le temps",
x = "Temps", y = "Contribution aux prospects") +
scale_fill_brewer(palette = "Set1") +
theme(legend.title = element_blank())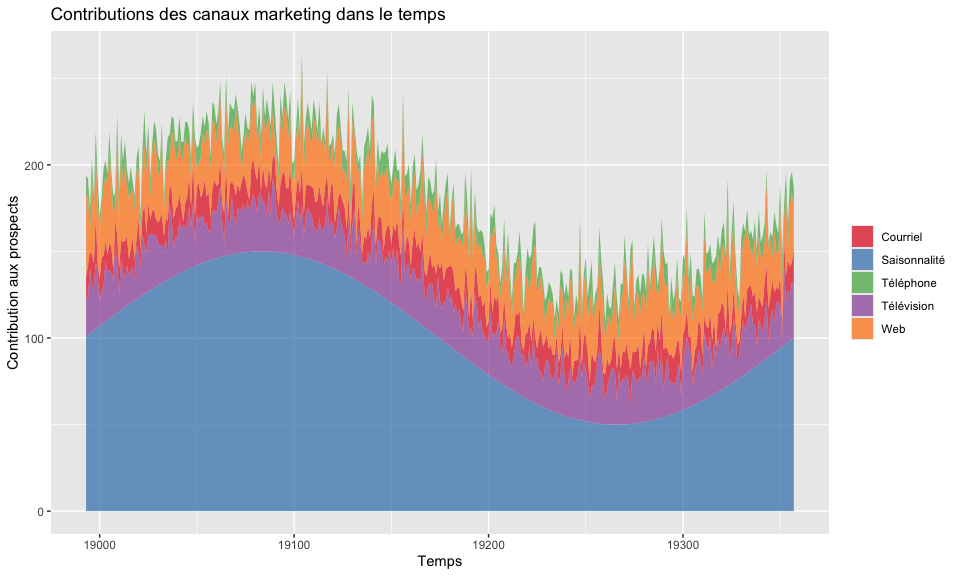
🌘 Données externes et géospatiales
R fournit des outils puissants pour travailler avec des données géospatiales, permettant l’intégration de jeux de données externes avec des composantes géographiques :
# Charger les packages requis
library(sp)
library(leaflet)
# Créer des données géospatiales synthétiques
set.seed(42)
n_regions <- 20
# Générer des coordonnées aléatoires pour les régions au Canada
regions_data <- data.frame(
region_id = paste0("REG", 101:120),
region_name = paste("Région", 1:20),
longitude = runif(n_regions, min = -141, max = -52), # Étendue de longitude du Canada
latitude = runif(n_regions, min = 42, max = 83), # Étendue de latitude du Canada
alert_severity = sample(c("Faible", "Moyen", "Élevé", "Critique"),
n_regions, replace = TRUE,
prob = c(0.4, 0.3, 0.2, 0.1)),
population = round(runif(n_regions, min = 1000, max = 50000)),
economic_activity = round(runif(n_regions, min = 100, max = 5000))
)
# Note: Pour leaflet, pas besoin de convertir en SpatialPointsDataFrame
# Créer le contenu des fenêtres contextuelles
regions_data$popup <- paste0(
"<strong>Région: </strong>", regions_data$region_name, "<br>",
"<strong>Gravité: </strong>", regions_data$alert_severity, "<br>",
"<strong>Population: </strong>", format(regions_data$population, big.mark = ","), "<br>",
"<strong>Activité économique: </strong>", format(regions_data$economic_activity, big.mark = ",")
)
# Créer une carte interactive
map_result <- leaflet(data = regions_data) %>%
addTiles() %>%
addCircleMarkers(
lng = ~longitude,
lat = ~latitude,
radius = ~ifelse(population > 25000, 8,
ifelse(population > 10000, 6, 4)),
color = ~case_when(
alert_severity == "Faible" ~ "green",
alert_severity == "Moyen" ~ "yellow",
alert_severity == "Élevé" ~ "orange",
alert_severity == "Critique" ~ "red"
),
stroke = TRUE,
fillOpacity = 0.7,
popup = ~popup
) %>%
addLegend(
position = "bottomright",
title = "Gravité de l'alerte",
colors = c("green", "yellow", "orange", "red"),
labels = c("Faible", "Moyen", "Élevé", "Critique"),
opacity = 1
)
map_result🌘 Conclusion
Le logiciel libre R fournit aux entreprises une plateforme puissante et flexible pour l’analyse de données et la prise de décision. Ses principaux avantages incluent :
- Portabilité des connaissances : Les employés apportent des compétences précieuses de leurs milieux académiques et professionnels
- Efficacité des coûts : Élimine les coûts de licence et de formation de logiciels propriétaires
- Accélération de l’innovation : Accès aux techniques statistiques et d’apprentissage automatique de pointe
- Collaboration interfonctionnelle : Outils standardisés à travers les unités d’affaires
En tirant parti de l’écosystème de packages étendu et de la communauté active de R, les entreprises peuvent développer des capacités analytiques robustes tout en maintenant la flexibilité et en réduisant la dépendance aux fournisseurs. Les exemples présentés ici démontrent des applications pratiques dans les assurances, le marketing et l’analyse géospatiale - tous utilisant des outils libres qui peuvent être librement adoptés et personnalisés.
🌘 Pour débuter
Pour commencer à utiliser R dans votre entreprise :
- Installer R : Télécharger depuis CRAN
- Choisir un IDE : RStudio fournit un excellent environnement de développement
- Explorer les packages : Parcourir CRAN pour des packages spécifiques à votre domaine
- Construire une expertise interne : Créer des groupes d’utilisateurs internes et des plateformes de partage de connaissances
- Intégrer progressivement : Commencer avec des projets pilotes et étendre en fonction du succès
La nature libre de R garantit que votre investissement dans les capacités analytiques continuera de croître avec le langage et sa communauté dynamique.